Register for Summer 1 Program Through the Feith Family Ymca
by William W Wold
I wrote a programming linguistic communication. Hither'southward how y'all can, too.
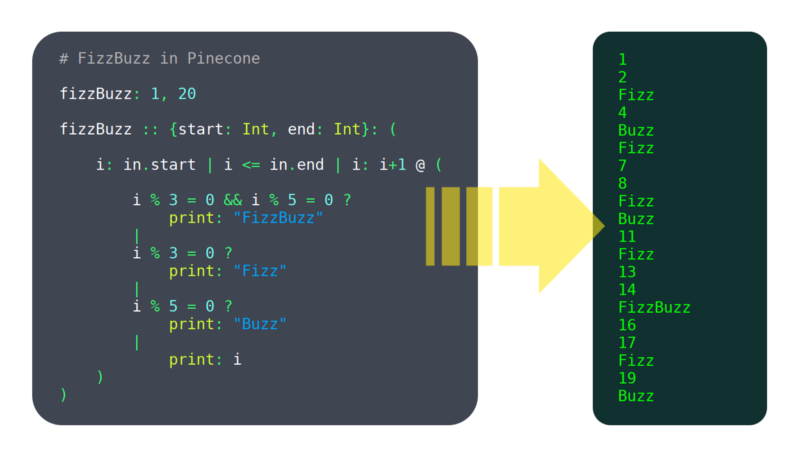
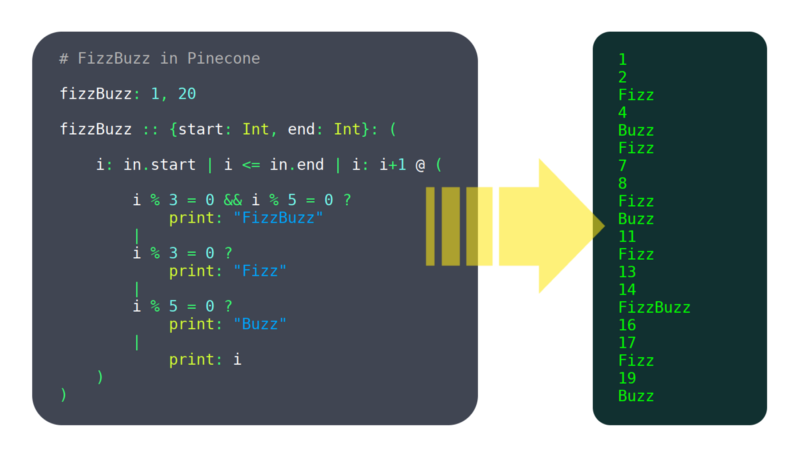
Over the past vi months, I've been working on a programming language called Pinecone. I wouldn't call it mature withal, but it already has enough features working to be usable, such equally:
- variables
- functions
- user divers structures
If you're interested in it, bank check out Pinecone's landing page or its GitHub repo.
I'm not an expert. When I started this project, I had no clue what I was doing, and I still don't. I've taken zippo classes on language creation, read but a flake well-nigh information technology online, and did non follow much of the advice I have been given.
And yet, I still made a completely new language. And it works. So I must be doing something right.
In this post, I'll dive under the hood and show you the pipeline Pinecone (and other programming languages) use to plow source code into magic.
I'll as well touch on some of the tradeoffs I've had make, and why I made the decisions I did.
This is by no ways a complete tutorial on writing a programming language, but it's a good starting indicate if you're curious about language development.
Getting Started
"I have admittedly no idea where I would even start" is something I hear a lot when I tell other developers I'm writing a language. In case that's your reaction, I'll at present get through some initial decisions that are made and steps that are taken when starting any new language.
Compiled vs Interpreted
In that location are 2 major types of languages: compiled and interpreted:
- A compiler figures out everything a programme will do, turns it into "machine code" (a format the computer tin can run really fast), so saves that to be executed after.
- An interpreter steps through the source code line by line, figuring out what information technology's doing equally it goes.
Technically any language could be compiled or interpreted, only 1 or the other usually makes more sense for a specific linguistic communication. Mostly, interpreting tends to exist more flexible, while compiling tends to have higher performance. Merely this is just scratching the surface of a very complex topic.
I highly value operation, and I saw a lack of programming languages that are both high performance and simplicity-oriented, so I went with compiled for Pinecone.
This was an important conclusion to make early on, because a lot of language blueprint decisions are afflicted by information technology (for example, static typing is a big benefit to compiled languages, but not so much for interpreted ones).
Despite the fact that Pinecone was designed with compiling in listen, information technology does take a fully functional interpreter which was the simply way to run it for a while. In that location are a number of reasons for this, which I volition explicate later.
Choosing a Language
I know it's a scrap meta, but a programming language is itself a program, and thus you need to write it in a language. I chose C++ because of its performance and big characteristic set. Also, I actually do relish working in C++.
If you are writing an interpreted language, information technology makes a lot of sense to write it in a compiled ane (like C, C++ or Swift) because the performance lost in the language of your interpreter and the interpreter that is interpreting your interpreter will chemical compound.
If you plan to compile, a slower language (like Python or JavaScript) is more acceptable. Compile time may exist bad, but in my stance that isn't nearly as big a deal as bad run time.
High Level Design
A programming linguistic communication is generally structured equally a pipeline. That is, it has several stages. Each stage has data formatted in a specific, well divers way. It also has functions to transform information from each stage to the side by side.
The beginning phase is a cord containing the unabridged input source file. The terminal stage is something that can be run. This will all get clear as we go through the Pinecone pipeline step by stride.
Lexing

The beginning step in near programming languages is lexing, or tokenizing. 'Lex' is short for lexical analysis, a very fancy word for splitting a bunch of text into tokens. The give-and-take 'tokenizer' makes a lot more than sense, just 'lexer' is so much fun to say that I use it anyway.
Tokens
A token is a small-scale unit of measurement of a language. A token might be a variable or function name (AKA an identifier), an operator or a number.
Task of the Lexer
The lexer is supposed to take in a string containing an entire files worth of source code and spit out a list containing every token.
Time to come stages of the pipeline will non refer back to the original source lawmaking, and so the lexer must produce all the data needed by them. The reason for this relatively strict pipeline format is that the lexer may practice tasks such every bit removing comments or detecting if something is a number or identifier. You want to keep that logic locked inside the lexer, both so you don't have to think about these rules when writing the residual of the language, and and so you lot can change this type of syntax all in ane identify.
Flex
The day I started the language, the first matter I wrote was a uncomplicated lexer. Soon subsequently, I started learning about tools that would supposedly make lexing simpler, and less buggy.
The predominant such tool is Flex, a program that generates lexers. Yous give it a file which has a special syntax to depict the language's grammar. From that it generates a C programme which lexes a string and produces the desired output.
My Decision
I opted to go along the lexer I wrote for the time existence. In the finish, I didn't see significant benefits of using Flex, at least non enough to justify adding a dependency and complicating the build process.
My lexer is only a few hundred lines long, and rarely gives me any problem. Rolling my own lexer besides gives me more flexibility, such as the ability to add an operator to the language without editing multiple files.
Parsing

The 2d stage of the pipeline is the parser. The parser turns a list of tokens into a tree of nodes. A tree used for storing this type of data is known as an Abstract Syntax Tree, or AST. At least in Pinecone, the AST does not accept any info about types or which identifiers are which. It is but structured tokens.
Parser Duties
The parser adds construction to to the ordered list of tokens the lexer produces. To stop ambiguities, the parser must have into account parenthesis and the society of operations. But parsing operators isn't terribly difficult, but as more language constructs get added, parsing can become very complex.
Bison
Once more, there was a decision to brand involving a tertiary political party library. The predominant parsing library is Bison. Bison works a lot like Flex. You lot write a file in a custom format that stores the grammar information, and then Bison uses that to generate a C plan that will do your parsing. I did not choose to employ Bison.
Why Custom Is Amend
With the lexer, the decision to utilise my ain code was adequately obvious. A lexer is such a piddling programme that not writing my own felt almost as silly as not writing my own 'left-pad'.
With the parser, it'southward a different thing. My Pinecone parser is currently 750 lines long, and I've written iii of them because the first two were trash.
I originally made my decision for a number of reasons, and while it hasn't gone completely smoothly, well-nigh of them hold true. The major ones are as follows:
- Minimize context switching in workflow: context switching between C++ and Pinecone is bad enough without throwing in Bison's grammar grammar
- Keep build simple: every fourth dimension the grammar changes Bison has to be run before the build. This can exist automated just it becomes a hurting when switching between build systems.
- I like edifice absurd shit: I didn't brand Pinecone because I idea it would exist piece of cake, and so why would I consul a central role when I could do it myself? A custom parser may not be footling, merely it is completely doable.
In the beginning I wasn't completely sure if I was going down a viable path, simply I was given conviction past what Walter Bright (a programmer on an early version of C++, and the creator of the D language) had to say on the topic:
"Somewhat more controversial, I wouldn't bother wasting time with lexer or parser generators and other so-called "compiler compilers." They're a waste of time. Writing a lexer and parser is a tiny percentage of the chore of writing a compiler. Using a generator will take upwardly about as much time every bit writing one by hand, and information technology will marry you to the generator (which matters when porting the compiler to a new platform). And generators besides take the unfortunate reputation of emitting lousy fault messages."
Activeness Tree
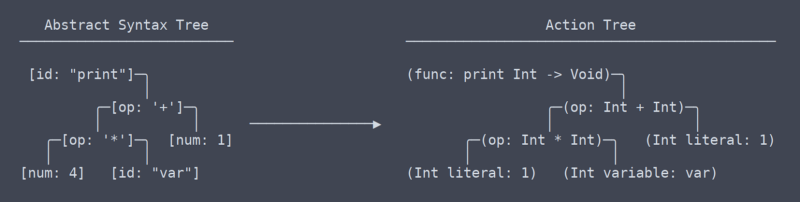
We have at present left the the area of mutual, universal terms, or at least I don't know what the terms are anymore. From my understanding, what I call the 'activeness tree' is most akin to LLVM'due south IR (intermediate representation).
There is a subtle but very pregnant difference between the action tree and the abstract syntax tree. It took me quite a while to figure out that at that place even should be a difference betwixt them (which contributed to the need for rewrites of the parser).
Activeness Tree vs AST
Put but, the action tree is the AST with context. That context is info such as what type a function returns, or that two places in which a variable is used are in fact using the same variable. Because it needs to figure out and remember all this context, the code that generates the action tree needs lots of namespace lookup tables and other thingamabobs.
Running the Activeness Tree
Once we have the action tree, running the code is piece of cake. Each action node has a function 'execute' which takes some input, does any the action should (including possibly calling sub action) and returns the activeness'south output. This is the interpreter in activity.
Compiling Options
"Merely wait!" I hear you say, "isn't Pinecone supposed to by compiled?" Yes, it is. Merely compiling is harder than interpreting. There are a few possible approaches.
Build My Own Compiler
This sounded similar a good idea to me at starting time. I exercise love making things myself, and I've been itching for an alibi to become practiced at assembly.
Unfortunately, writing a portable compiler is not every bit like shooting fish in a barrel as writing some machine code for each language element. Because of the number of architectures and operating systems, it is impractical for any individual to write a cross platform compiler backend.
Even the teams behind Swift, Rust and Clang don't want to carp with it all on their ain, and so instead they all use…
LLVM
LLVM is a collection of compiler tools. It'due south basically a library that will turn your linguistic communication into a compiled executable binary. It seemed like the perfect choice, and then I jumped right in. Sadly I didn't check how deep the water was and I immediately drowned.
LLVM, while not assembly language hard, is gigantic complex library hard. It's not incommunicable to use, and they have good tutorials, merely I realized I would have to get some practice before I was set up to fully implement a Pinecone compiler with it.
Transpiling
I wanted some sort of compiled Pinecone and I wanted it fast, so I turned to one method I knew I could make work: transpiling.
I wrote a Pinecone to C++ transpiler, and added the power to automatically compile the output source with GCC. This currently works for almost all Pinecone programs (though there are a few edge cases that break information technology). It is non a peculiarly portable or scalable solution, merely it works for the time being.
Future
Bold I continue to develop Pinecone, It will become LLVM compiling support sooner or afterward. I doubtable no mater how much I work on information technology, the transpiler will never be completely stable and the benefits of LLVM are numerous. It's just a matter of when I have time to make some sample projects in LLVM and get the hang of it.
Until and then, the interpreter is great for trivial programs and C++ transpiling works for most things that need more performance.
Conclusion
I hope I've fabricated programming languages a niggling less mysterious for you. If yous practice desire to brand one yourself, I highly recommend it. At that place are a ton of implementation details to figure out only the outline here should be plenty to get you going.
Here is my loftier level advice for getting started (call up, I don't really know what I'g doing, so accept information technology with a grain of salt):
- If in incertitude, go interpreted. Interpreted languages are generally easier pattern, build and acquire. I'm not discouraging you lot from writing a compiled ane if y'all know that's what you desire to exercise, but if you lot're on the contend, I would go interpreted.
- When information technology comes to lexers and parsers, exercise whatsoever yous want. There are valid arguments for and against writing your own. In the end, if you retrieve out your design and implement everything in a sensible way, it doesn't really matter.
- Learn from the pipeline I concluded up with. A lot of trial and fault went into designing the pipeline I accept now. I have attempted eliminating ASTs, ASTs that turn into actions trees in place, and other terrible ideas. This pipeline works, so don't modify it unless you have a really good thought.
- If y'all don't take the time or motivation to implement a complex general purpose language, try implementing an esoteric language such every bit Brainfuck. These interpreters tin can be as short as a few hundred lines.
I accept very few regrets when information technology comes to Pinecone development. I made a number of bad choices forth the way, only I have rewritten virtually of the lawmaking afflicted by such mistakes.
Correct now, Pinecone is in a good plenty state that it functions well and can be easily improved. Writing Pinecone has been a hugely educational and enjoyable experience for me, and information technology'southward just getting started.
Larn to code for gratis. freeCodeCamp's open up source curriculum has helped more than than 40,000 people go jobs as developers. Get started
gonzalesdreff1942.blogspot.com
Source: https://www.freecodecamp.org/news/the-programming-language-pipeline-91d3f449c919/
0 Response to "Register for Summer 1 Program Through the Feith Family Ymca"
Post a Comment